11 minutes
Introduction to eBPF
Before you will spend the next 10 to 20 minutes reading about eBPF, let me say a few words to start this blog. This is my first blog post and it originates from a paper I had to write for class in Uni a couple of months ago.
I really enjoyed learning about eBPF and thought it’s a good topic to start my own blog, with the goal of posting here once in a while about tech stuff I have been working or playing with. If you find things that are wrong and need to be corrected, or just want to contact me for other reasons, feel free to reach out through any forms of contact mentioned on this website.
That’s all I have to say really, so lets get into the cool stuff.
The extended Berkeley Packet Filter (eBPF) provides a way of accessing in-kernel data structures and functions, which enables processing data directly in the kernel without copying it to user-space.
In this post, we will talk about eBPF. Starting with its predecessor called BPF, initially described by McCanne and Jacobson, I will also explain eBPFs architecture and cover how security risks introduced by the concept of executing user-space code in kernel-space are mitigated.
Why do we need eBPF?
Lots of programs, e.g. network monitors, run as user-level processes. In order to analyze data that passes only through the kernel, they have to copy that data into user-space memory and perform context switches. That results in a significant performance overhead compared to analyzing that data directly inside the kernel.
Additionally, network speeds and traffic volumes have increased exponentially in recent years. Certain applications have to handle huge amounts of data. For example, the video-streaming service Netflix is accountable for about 15% of the global downstream volume.
At some point, monitoring that much traffic only in user-space is no longer feasible and one solution is to use eBPF programs.
Besides performance benefits, eBPF programs offer safety and flexibility as it is possible to write and compile eBPF programs at run-time. By not doing any direct kernel programming (e.g. kernel modules), we avoid recompiling the kernel with every change. We also prevent resource lock-ups, potential memory corruption, entire system crashes and introducing security risks.
What is eBPF?
The eBPF is a full VM inside the kernel, that allows user-space programs to access a subset of kernel functions. One of the main advantages of eBPF is that you do not have to write kernel modules and there is no need to recompile the kernel for eBPF programs to take effect.
Programs can live in user-space, load the eBPF part of the program into the kernel, then get processed and attached to the correct place by the eBPF VM. The user-space program can then read any results from the eBPF program it loaded via data structures (eBPF maps) that are readable in user-space.
The kernel functions that are accessible by eBPF are mostly used for tracing and filtering directly inside the kernel.
A bit of history
The BSD Packet Filter
BPF was introduced in 1992 in the paper The BSD Packet Filter: A New Architecture for User-level Packet Capture. At the time of writing, BPF was about two years old and running in the BSD Kernel. McCanne and Jacobson defined BPF to have two main components:
- The network tap that collects packets from the network driver and forwards them to listening filter applications.
- The packet filter, realized by an in-kernel VM that runs bytecode which will perform the filtering actions.
Overall, they describe BPF as a very well performing tool to monitor, capture, and filter networking packets. The paper continues with a comparison of BPF to other filtering mechanisms, which are shown to be outperformed by BPF.
McCanne and Jacobson also outline some of the design constraints for BPF. Two of them are important for its future development:
- “It must be protocol independent. The kernel should not have to be modified to add new protocol support.”
- “It must be general. The instruction set should be rich enough to handle unforeseen uses.”
Those constraints allowed BPF to transform into what we know as eBPF today.
Extended BPF
While BPF was proven to have good performance, in 2013 Alexei Starovoitov proposed the extended BPF.
Building upon the generality and protocol independence of BPF, his proposal allowed read-only access to certain in-kernel data structures. This enables many more tracing capabilities for eBPF since it is not just limited to networking functions.
Starovoitov also introduced some changes to modernize the architecture and further improve performance. Most notably:
- The instruction set was extended. BPF had two 32-bit registers, eBPF has eleven 64-bit registers.
- eBPF uses Just-In-Time (JIT) compilation.
- It is possible to write eBPF programs in restricted C.
In March 2016, Branden Gregg posted an article on his blog arguing that eBPF brings “superpowers” to Linux. He describes how eBPF gives him much more insight into Netflix’s production servers and introduces the BPF Compiler Collection (BCC).
This set of tools he and others developed are making use eBPFs tracing functionalities to give various insights into the operating system stack. Today BCC also offers various Programming language (Go, Python, etc.) support to write eBPF programs.
Architecture
In this section, we will see the higher level architecture of eBPF as well as some details on the VM design.
When talking about VMs, most people will think of virtualization and containerization. These are techniques to abstract the hardware or operating system level to higher level software. In the case of eBPFs VM this is not true. The eBPF VM translates eBPF bytecode into native code, just as the JVM translates java bytecode.
Executing user-space code in the kernel introduces some risks. The common understanding without eBPF is a strict split between user-space and kernel-space. So how does eBPF guarantee safety when breaking that model? To answer that question, the section introduces the Verifier.
Program flow
To show the higher level architecture of eBPF lets go over the program flow of a user writing code that leverages eBPF to access kernel-space functions:
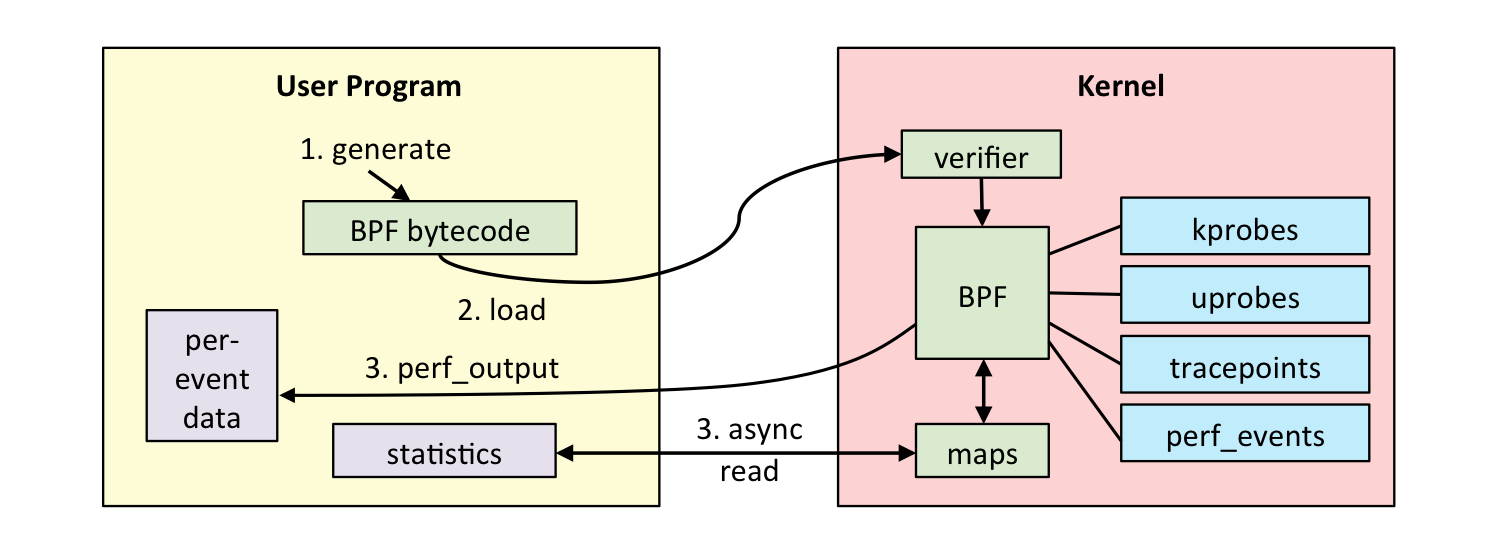
- A user-space program has to generate eBPF bytecode. To do this a user can either write C code, use existing tools, or an available programming language extension which can be found in the BCC.
- The generated bytecode needs to be loaded into the Kernel. For that Linux has introduced a new system call: bpf(). It is available in Linux since v.3.18 (released in December 2014), which was the first release to include eBPF.
- The eBPF bytecode gets verified by the Verifier. We will look into its specific role later but its purpose is to verify the loaded bytecode to be safe for execution inside the kernel.
- The eBPF VM JIT-compiles the bytecode into native code for the underlying architecture and attaches it to the correct place. The image above shows various examples of in-kernel functions to use. E.g. kprobes was developed to do dynamic kernel tracing or its user- level equivalent uprobes which enables dynamic user- level tracing.
- eBPF has two ways of communicating back to user-space. It can either emit per-event details, or write results into BPF maps that are readable by the user program. These maps can represent arrays, hash maps, histograms and other common data structures.
A VM inside the kernel
Now that we understand the higher-level architecture and the program flow of running eBPF programs, we want to look at some details of the VM itself. The eBPF VM is a Reduced Instruction Set Computer (RISC) register machine.
This means that eBPF, as any hardware Instruction Set (x86, amd64, ARM), has its own instructions and a number of registers, reduced to the functionality of calling in-kernel functions.
Starovoitov described this RISC register machine in his first eBPF proposal. eBPF has eleven registers and its calling convention is defined as follows:
- R0 is the return register for in-kernel helper functions.
- R1 — R5 are in-kernel function argument registers.
- R6 — R9 are callee saved registers.
- R10 is a read-only frame pointer register to access the stack.
While eBPF already enables for faster execution of these programs due to running them directly in the kernel and saving on context switches between user-space and the kernel, this design allows for minimal performance overhead as well because eBPFs bytecode instruction set and all its eleven registers can be mapped 1-to-1 with modern 64-bit hardware architectures (x86, amd64, ARM) when JIT-compiling to native code.
The Verifier
As tempting it seems to execute user-space code directly in kernel-space, it should immediately raise security questions. There is a reason why the original operating system design separates these two address spaces. Operating system security is deeply rooted in the user/kernel split design. But eBPF has a solution to that problem.
The solution is to verify the code for safety by the Verifier. Code verification is a complex problem, unsolvable even if you try to verify arbitrary code for its outcome as proven by Alan Turing in 1936 with the halting problem.
That means the Verifier needs to impose certain limitations on the code we are able to execute in the kernel with eBPF. While this of course implicates drawbacks for the power of eBPF, it is a necessary part of running untrusted code in the kernel.
Starovoitov’s proposal essentially outlines the following protection mechanisms used by the Verifier:
- Run a Depth-First-Search to disallow loops.
- Simulate an eBPF program instruction for instruction and check register contents.
These mechanisms have big implications for eBPF programs:
- They are not Turing complete because we do not allow endless loops. This is very important to satisfy one of the motivations mentioned in the beginning.
- We are able to avoid problems such as system lockups. If a user were able to submit a eBPF program containing an endless loop, that would effectively enable a Denial-of- Service attack on our system.
- There is a fixed instruction limit per program
- The Verifier checks for memory safety when accessing specific kernel addresses.
Overall the Verifier gives us the guarantees we need to even consider executing user-space code in kernel-space. Apart from the listed limitations, making use of eBPF can give users great insights into their system without worrying about sabotaging or destroying their system.
Implementation Example
My hope is that after getting this introduction to eBPF some of you want to play with it as well. While you can go much deeper, I want to at least provide a small practical example. I stole it from the paper introducing eXpress Data Path (XDP). I really recommend reading it as it shows great performance benchmarks achieved leveraging eBPF. TL;DR; XDP moves network processing directly into the kernel.
Disclaimer: The practical part will only work for people using a Linux machine as eBPF is a feature available in Linux.
Dropping UDP packets with eBPF
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/in.h>
#include <linux/ip.h>
#include <linux/ipv6.h>
#include <linux/udp.h>
#include <stdint.h>
#define SEC(NAME) __attribute__((section(NAME), used))
#define htons(x) ((__be16)___constant_swab16((x)))
SEC("prog")
int xdp_drop_benchmark_traffic(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
struct ethhdr *eth = data;
uint64_t nh_off = sizeof(*eth);
if (data + nh_off > data_end)
{
return XDP_PASS;
}
uint16_t h_proto = eth->h_proto;
int i;
if (h_proto == htons(ETH_P_IP))
{
struct iphdr *iph = data + nh_off;
struct udphdr *udph = data + nh_off + sizeof(struct iphdr);
if (udph + 1 > (struct udphdr *)data_end)
{
return XDP_PASS;
}
if (iph->protocol == IPPROTO_UDP && udph->dest == htons(5001))
{
return XDP_DROP;
}
}
return XDP_PASS;
}
char _license[] SEC("license") = "GPL";
This code snippet shows a simple XDP program that drops UDP packets on port 5001. In our example we will hook that directly into the network driver and it will be run on every packet that the network driver processes. So on every packet we receive this code will check if its belonging to the right protocol, UDP, and then tell XDP to drop or keep the packet.
To compile this code we are going to use the clang compiler:
clang -I/usr/include/x86_64-linux-gnu -O2 -target bpf -c udp-drop.c -o udp-drop.o
Now we can load this XDP program into the kernel using iproute because it has a XDP extension:
sudo ip link set dev eth0 xdp obj udp-drop.o
And thats all we need. Test it with a simple iperf performance test:
iperf -u -s # conveniently starts up a UDP server on port 5001 ;)
iperf -c 127.0.0.1 -u -b 100m # send packets to our iperf UDP server
Feel free to use other tests to send UDP packets on a specific port, the result should be the same: the server will not receive any packets as they were dropped in the kernel.
Conclusion
eBPF gives us great power and safety when it comes to monitoring and tracing in production systems.
Its power and safety are not only a nice-to-have feature but are becoming undoubtedly necessary with today’s network speeds and traffic volumes for a growing number of applications. While the idea of breaking the strict user/kernel split was born in the 90s with BPF, eBPF is still in its early stages and needs continuous improvement.
From a user experience standpoint the eBPF VM and the Verifier still limit what you can do with eBPF programs. Using a user-space network monitor might give you more flexibility and ease of use.
Since eBPF is still considered to be in its early stages, we can expect future improvements with a growing user base. Already today, technologies such as XDP leverage the power of eBPF to implement network processing in the kernel and reach much higher performance in doing so.
If you want to know more
Besides the resources that are linked throughout this post I recommend checking out the following:
- Brendan Gregg and his talks on eBPF on Youtube
- If you want to see eBPF in action and be blown away by its performance, read this Paper on XDP and look at this blog post from Cloudflare
- For even more resources: ebpf.io
- Another cool project leveraging eBPF: cilium.io
2325 Words
2020-08-29 02:00 +0200